今天將介紹的是在現有的資料內新增表徵,可以理解為手上有一張從資料庫的table內撈出的資料紀錄,我們則手動在這筆資料內新增欄位。新增表徵的用意是什麼、表徵的值從哪來,將會一一作基本的說明。至於此篇則如文章標題一樣,介紹新增表徵的基本,於後面的篇章再行介紹對特定資料類型的表徵建構方法。建構新特徵的主題將會有以下獨立篇章,以資料類型分為:
有時候資料的表徵可以透過加入更精煉的訊息,讓我們在進行資料解讀的時候能夠更一目了然。舉例來說,titanic當中的Fare欄位式代表票價的資料,是代表該家庭的總票價。但是家庭人數是變數,每家的人數不盡相同。也許我們會遇到這一的情況:A家庭在總票價上花費為100元,B家庭花費50元,但是A家庭的家庭人口為10人,也就是10人的票價總共花了100元,而B家庭僅1人,1人便花費50元,因此人均的花費在此時更能幫助我們理解乘客消費的能力。但以現有的資料內並沒有人均消費的欄位,因此在現有資料範疇以外的資料,就得透過我們新增額外的欄位來產生。而有時新產生的表徵在機器學習的表現可能比原生資料來得更好、對要預測的目標線性關連更強...等等,將會透過範例實現。
以下示範新增欄位的過程:
import re
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
%matplotlib inline
#萬年起手式,從讀取資料開始
#各欄位的資料類型
column_types={'PassengerId':'category',
'Survived':int,
'Pclass':int,
'Name':'category',
'Sex':'category',
'Age':float,
'SibSp':int,
'Parch':int,
'Fare':float,
'Cabin':'object',
'Embarked':'category'}
#訓練集
train_set = pd.read_csv('data/train.csv', dtype=column_types)
#測試集
test_set = pd.read_csv('data/test.csv', dtype=column_types)
# merged = train_set
dataset = pd.concat([train_set, test_set])
家庭的總人數:
#新增家庭總人數的欄位
dataset['FamilySize'] = dataset.Parch + dataset.SibSp + 1
在新增人均票價欄位之前,我們必須先知道每個家庭的總人數,計算方式是加總乘客的親人數量的欄位後加1,1代表乘客本人,得出結果就是家庭的總人數。pandas可以幫助我們作資料欄位間的矩陣運算,因此我們要對欄位全部的值作運算,不管是加上另一個矩陣或是一個常量,都以一個加法操作就可以得到解。一起看看PANDAS幫我們做到的事情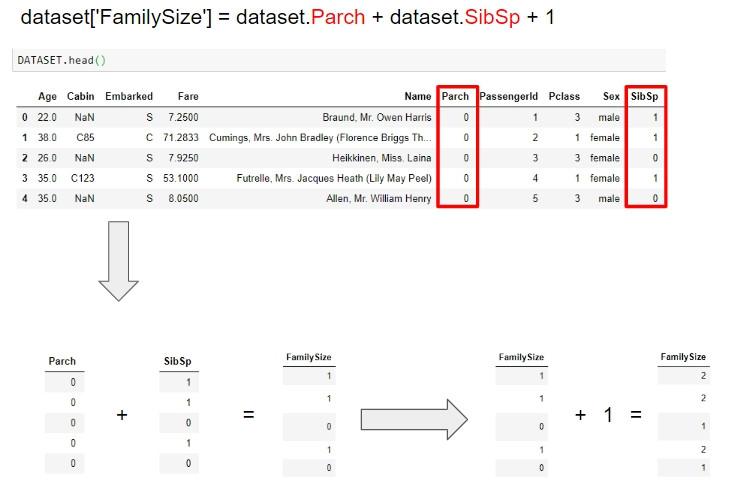
有了家庭總人數就可以進一步算人均消費:
#Fare值除以家庭總人口數==每個人花的票價
merged['AvgFare'] = merged['Fare'] / merged['FamilySize']
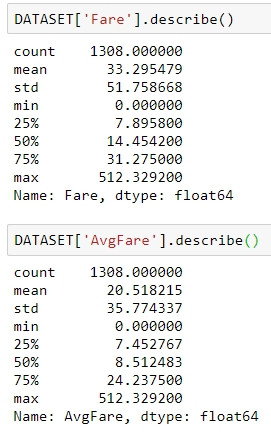
比對下統計的敘述差異很明顯(第N四分位數),而因為有了新的特徵我們得以從中捕捉到更多訊息(不像整體票價,以人均票價來看的話價錢還挺集中的)。
上例講述的都是定量資料的操作,在這裡提幾個定性資料的例子:
#import regex模組
import re
#對Name欄位作字串處理,產生新的"稱謂"欄位
#例:Mr Mrs. Miss...etc
merged['Title'] = merged.Name.apply(lambda _name:re.findall(r'.*\b(\w+)\..*', _name)[0])
#對Cabin欄位作字串處理 去除數字 僅留下船艙別
#example: C86 C64 C12 -> CCC
merged['Cabin'] = merged['Cabin'].fillna('unknown')
merged['Cabin'] = merged['Cabin'].apply(lambda _cabin:''.join([char for char in _cabin
if not char.isdigit()]).replace(" ", ""))
處理過的Cabin欄位還能讓我們進一步又產生新的"房間數量"欄位
#代表乘客所訂房間數量的新欄位
merged['NumberOfRoom'] = merged['Cabin'].apply(lambda cabin:len(cabin) if not pd.isnull(cabin) else np.nan)
有了pandas的方便功能,我們有很大的創造力來作出新的欄位。我們可以讓數值型欄位間互相作加減乘除、對文字形欄位做字串處理產生新的資料...等等更多應用,這都是倚賴對資料的觀察以及理解。值得一提的是有時候最有用的特徵是平常難以想像的,例如:(Fare + Age) / (NumberOfRoom * SibSp)這種看不出意義的新表徵,打敗了其他所有表徵,成為與生存率最高關聯性的表徵。這雖然是一個隨便的舉例且沒經過驗證,但只是用來表達這是在機器學習中屢見不鮮的例子。以下舉幾個例子:
#都看不出用途的新表徵
DATASET['FarePlusAge'] = DATASET.Fare + DATASET.Age
DATASET['FarePlusAgeDivideByFamilySize'] = (DATASET.Fare + DATASET.Age) / DATASET.FamilySize
再來看看本例作的新特徵跟生存率的關聯性的線性關係(藍色標記處為各表徵與生存率的線性關聯度,絕對數值越大關聯度越強):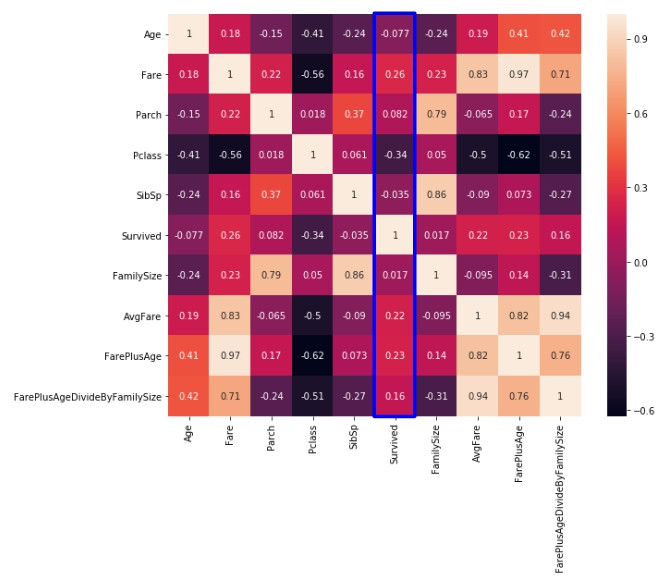
新增的兩個意義不明的欄位居然在關聯度上超越了如Age、Parch、SibSp等原生欄位,原因是什麼我也不知道,因為此兩欄位就是我隨意產生的結果,至於實際上具不具用處、能不能改善機器學習的準確度都需要實際驗證才能得知,除了要對資料的認知與理解才能做出好的表徵,有時候透過做各種表徵實驗也能幫助我們找到意想不到的驚喜。試試看吧!

